
CAP allows you to provide initial data for your application in CSV files. I noticed that a few are asking how to load initial test data for nested entities and many-to-many compositions. If you’ve never done this before, you too may be wondering how.
It’s pretty straightforward, so let’s get to it quickly.
An example with managed compositions
Suppose you want to compose an entity from several other entities with some additional attributes. For example, imagine a recipe that is composed of several ingredients. The “Ingredients” entity does not need to know the units of measurement or the amount to be added to the dish, but it is quite relevant to the recipe. A managed composition is a great way to meet this requirement.
You can use managed compositions of aspects to beautifully represent document structures in your domain models, without separate entities, reverse associations, and unmanaged power-on conditions.
So you want to link multiple ingredients to a recipe, adding more information that is not stored in the ingredients themselves. In addition, you want to navigate from a recipe to its ingredients and from an ingredient to the recipes that contain it. This is an example of an attributed many-to-many relationship. In the example shown below, we also use inline targets, meaning we do not specify aspects outside of the entity itself.

Managed compositions are primarily just a simplified notation. Behind the scenes, they are deployed like unmanaged compositions by automatically adding a new entity whose name CAP forms as a scoped name from the name of the parent entity followed by the name of the composition item, i.e. “Recipes.Ingredients” in the previous example.
Managed compositions are handy for many-to-many relationships where a link table is usually private to only one side. So far, however, we don’t know how to navigate from the individual ingredient to the recipe. This is because we have not looked at the “ingredients” entity. So let’s look at the entity “ingredients” to solve this problem.
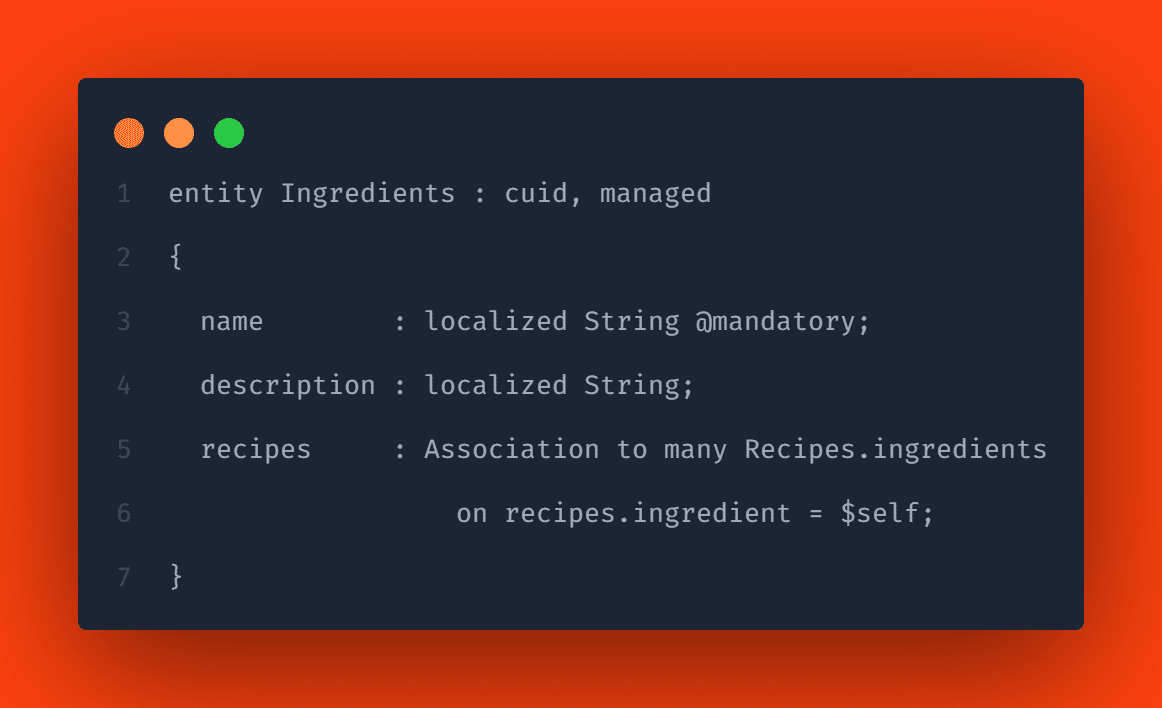
Loading the initial data for your entities is quite simple. CSV files in your project are fetched by deployments for both SQLite and SAP HANA. However, there are a few conventions that you must follow.
By convention, your csv files must be in a db/csv, db/data, or db/src/csv folder. A single csv file contains the data for one entity at a time. You must also follow the pattern <Namespace>-<EntityName>.csv. Since we have not defined a namespace in this example, the files for our entities are named “Recipes.csv” and “Ingredients.csv”.
The csv files must start with a header line listing the required element names. So let’s provide the initial data for one recipe and two ingredients by adding the two files Recipes.csv and Ingredients.csv in the db/data folder:
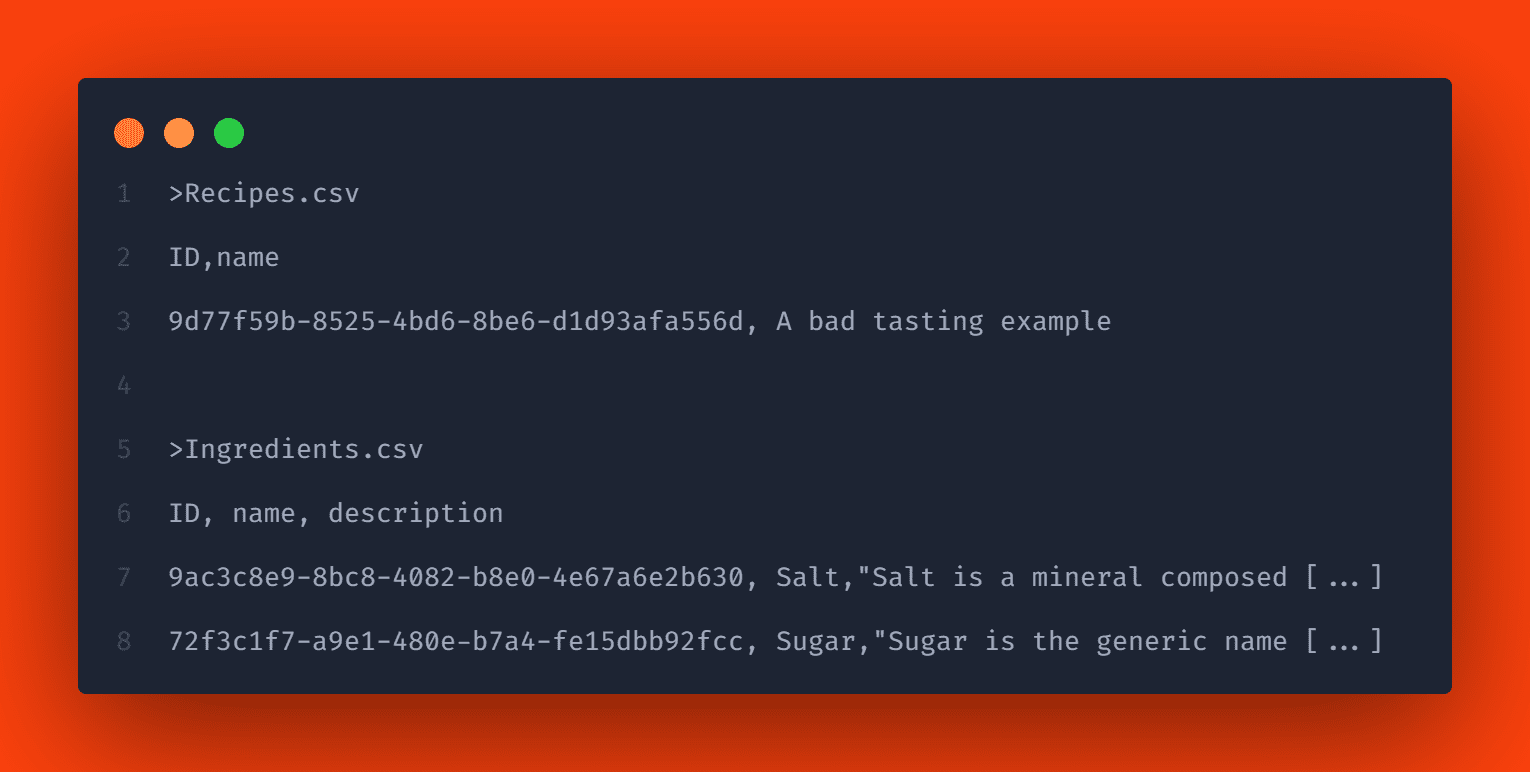
We have already provided data for some attributes. As you can see, we can add a single entry for the localized strings. CAP will use the entry we added with the default language. So next we need to enter translations for the localized fields.
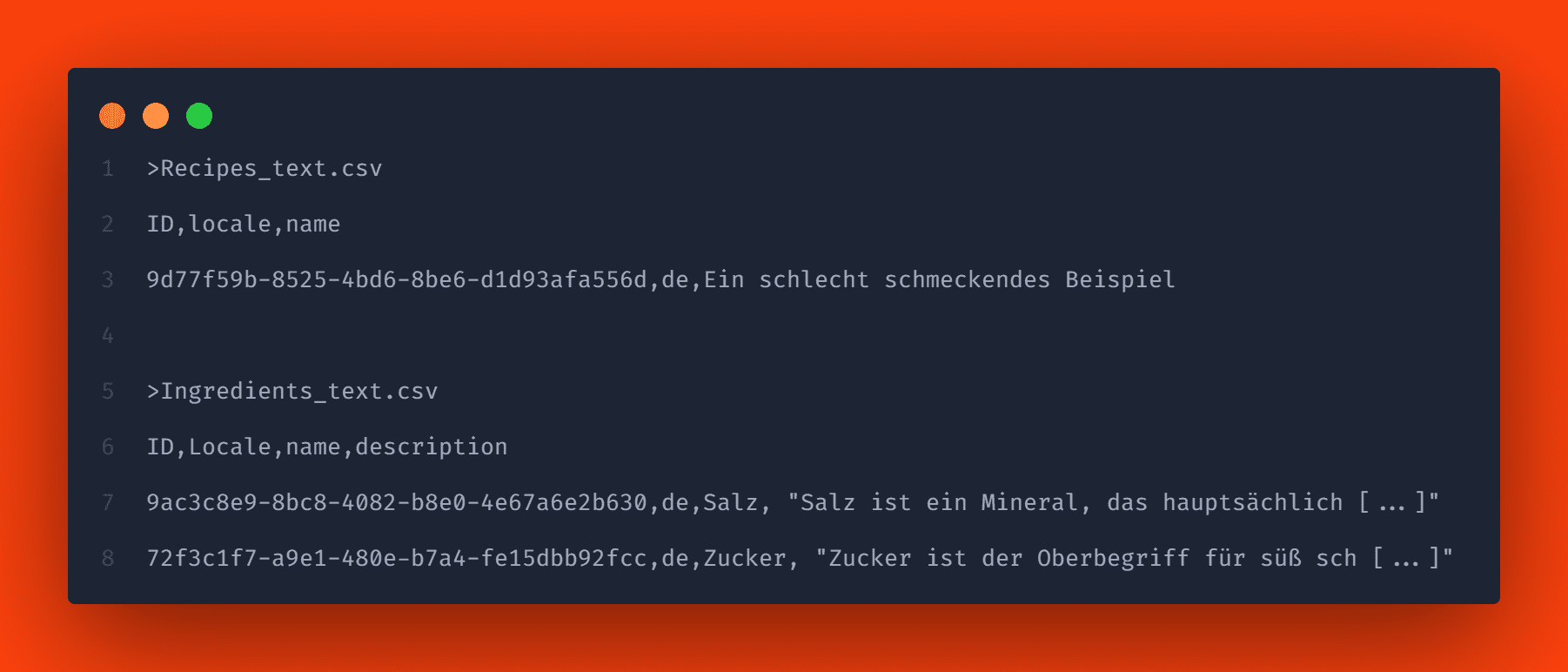
To add localized strings, you need to create csv files with the same naming scheme as before appending _texts. In our example, the csv files Recipes_texts.csv and Ingredients_texts.csv.
Now that the entity data and localizations are in place, let’s populate the composition. The naming scheme is here <Namespace>.<Entity name>-<Attribute>.csv. In our example, this would correspond to the Recipes-ingredients.csv file.
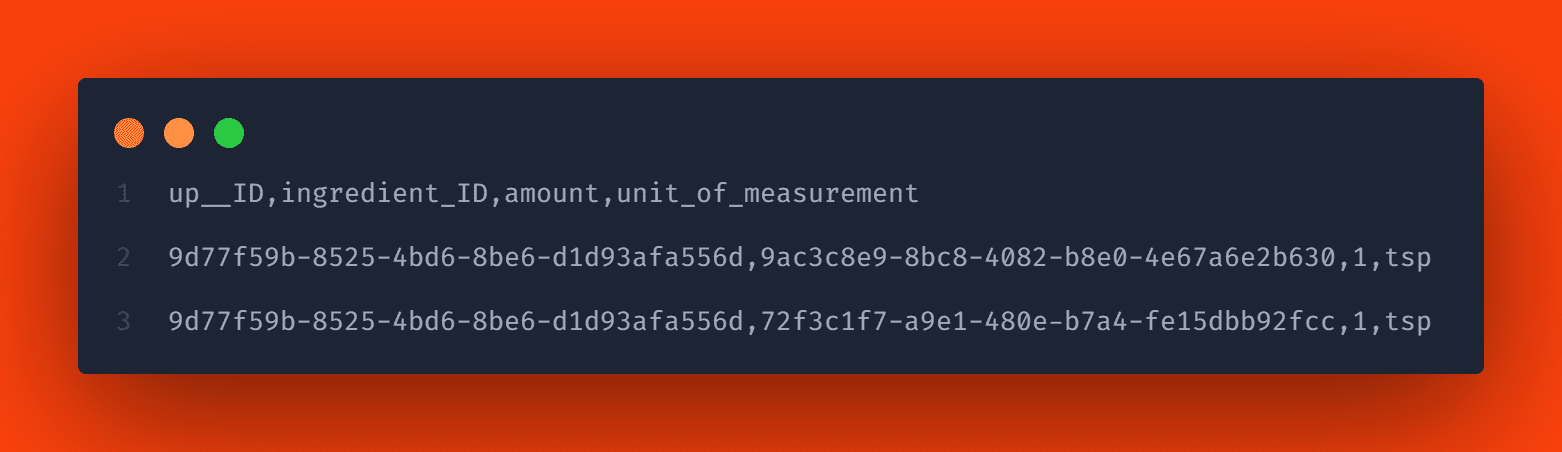
This csv file contains the columns up__ID and ingredients_ID. The column up__ID references the containing entity (Recipe), which has the key field ID with cuid. The ingredients_ID column is the association to the ingredient entity, which also has the ID key field.
This is how you set up the initial data. In the next section, we take a brief look at the results in action.
Perform test with a simple service
To test if the data is added by CAP, we can create a very simple service. Create the test-service.cds file in the srv folder and add projections to the two entities there. This could look like this, for example:
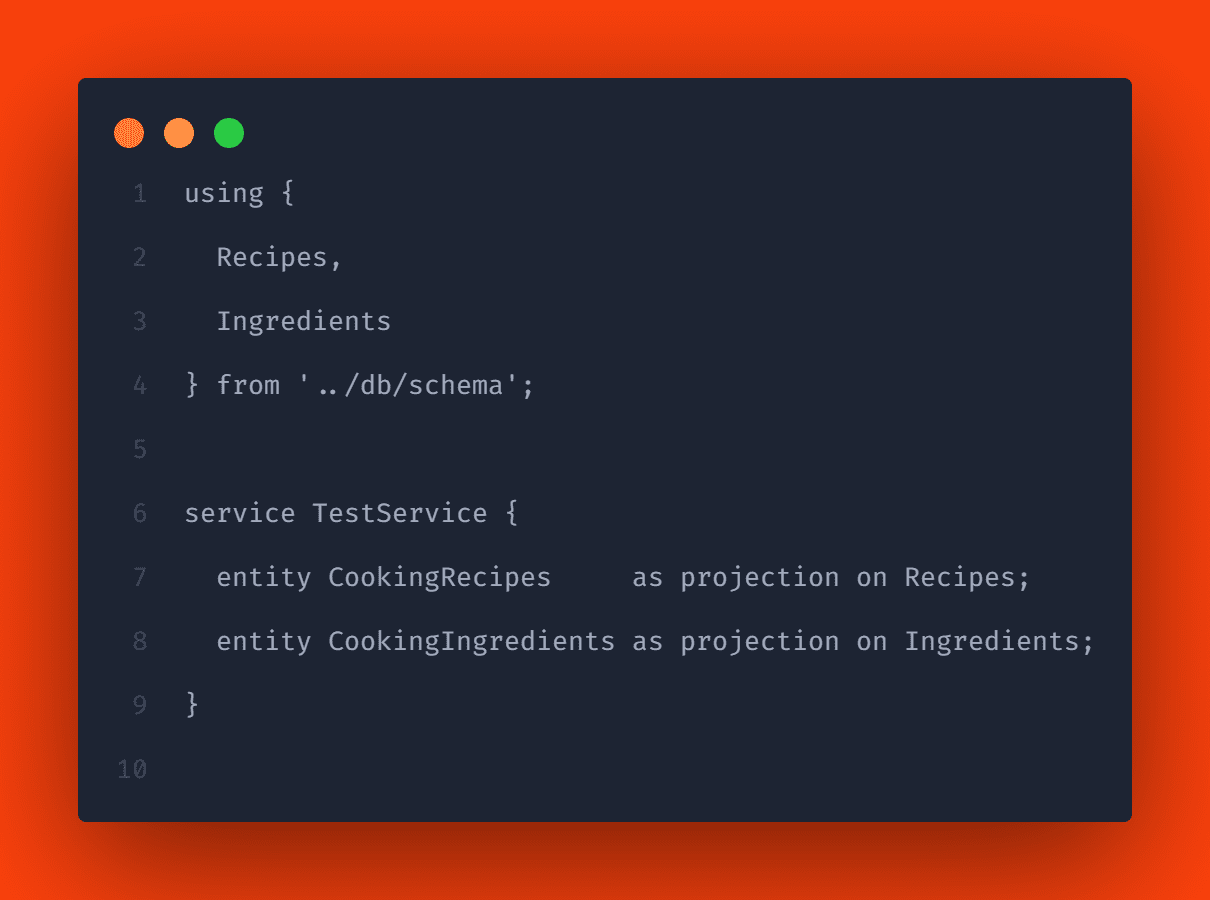
If you now run cds watch in the terminal, you will see an output stating that the files have been detected and their contents automatically loaded into the database:
[cds] - connect to db > sqlite { database: ':memory:' }
[cds] - using bindings from: { registry: '~/.cds-services.json' }
> filling Ingredients from .\db\data\Ingredients.csv
> filling Ingredients.texts from .\db\data\Ingredients_texts.csv
> filling Recipes.ingredients from .\db\data\Recipes-ingredients.csv
> filling Recipes from .\db\data\Recipes.csv
> filling Recipes.texts from .\db\data\Recipes_texts.csv
/> successfully deployed to sqlite in-memory db
This is the output when you use the example. Now let’s quickly use the started service to get an overview. To expand recipes to show ingredients, use an OData query such as:
GET http://localhost:4004/test/CookingRecipes?$expand=ingredients($expand=ingredient)
As you will notice, the answers are German, because we entered the localization and the default language of my browser is German.

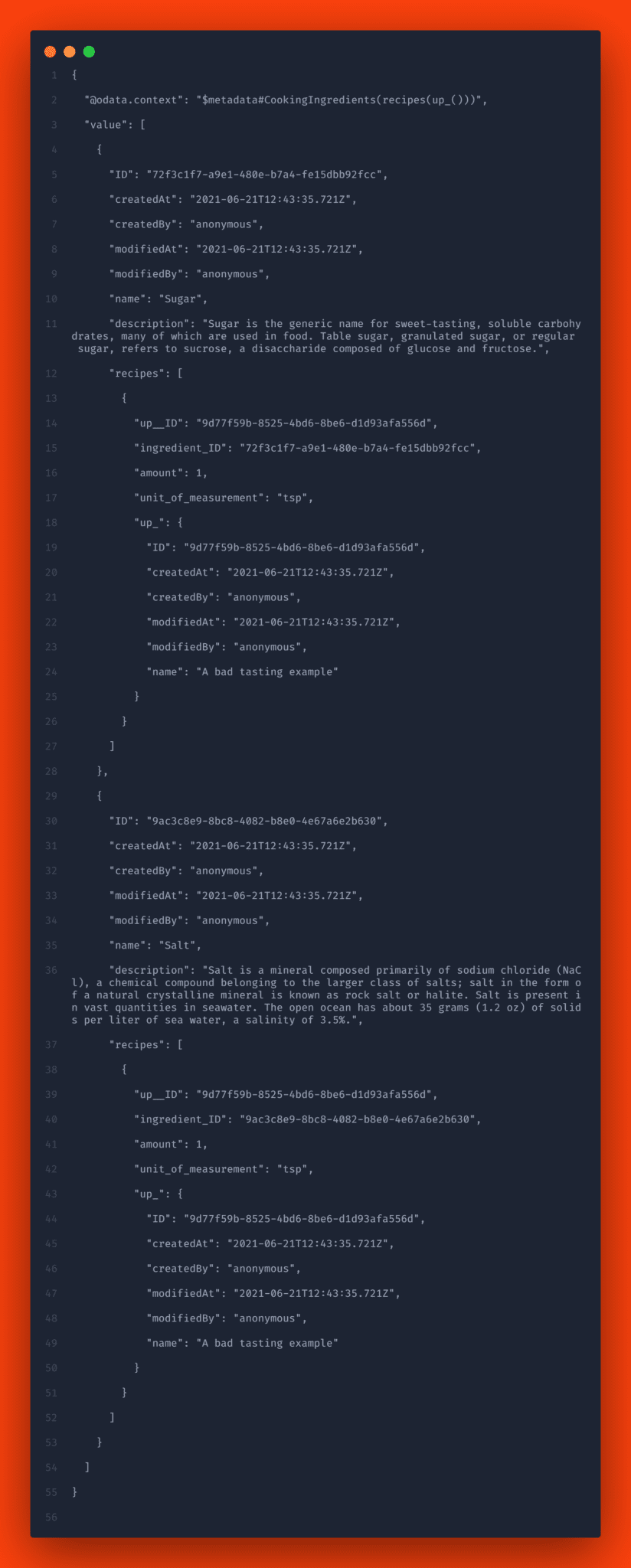
Let’s go the opposite way from an ingredient to a recipe, but this time with English results. For this we use a query like:
GET http://localhost:4004/test/CookingIngredients?$expand=recipes($expand=up_)&sap-language=en
You will receive a response such as:
Let’s recap briefly. You use compositions for document-oriented modeling and capture relationships contained in entities. You can model many-to-many relationships with Compositions of Aspects.
CAP runtimes provide out-of-the-box support for delivering structured document data through generic service provider implementations.
You can provide output data for Compositions of Aspects by creating csv files with the naming scheme <Namespace>.<Entity>-<Attribute> and provide references to the containing entity by providing columns to the key fields of the containing entity that start with up__.
If you have any further questions about this topic, please leave us a message.


