
CAP ermöglicht es Ihnen, initiale Daten für Ihre Anwendung in CSV-Dateien bereitzustellen. Es ist mir aufgefallen, dass einige sich fragen, wie man anfängliche Testdaten für verschachtelte Entitäten und Many-to-Many Kompositionen laden kann. Wenn Sie das noch nie gemacht haben, dann fragen auch Sie sich vielleicht, wie das geht.
Es ist recht unkompliziert, also lassen Sie es uns schnell anpacken.
Ein Beispiel mit verwalteten Kompositionen
Nehmen wir an, Sie möchten eine Entität aus mehreren anderen Entitäten mit einigen zusätzlichen Attributen zusammenstellen. Stellen Sie sich zum Beispiel ein Rezept vor, das aus mehreren Zutaten zusammengesetzt ist. Die Entität „Zutaten“ muss die Maßeinheiten oder die Menge, die in das Gericht gegeben werden soll, nicht kennen, aber für das Rezept ist es ziemlich relevant. Eine verwaltete Komposition ist eine hervorragende Möglichkeit, diese Anforderung zu erfüllen.
Sie können verwaltete Kompositionen von Aspekten verwenden, um Dokumentenstrukturen in Ihren Domänenmodellen schön darzustellen, ohne separate Entitäten, umgekehrte Assoziationen und nicht verwaltete Einschaltbedingungen.
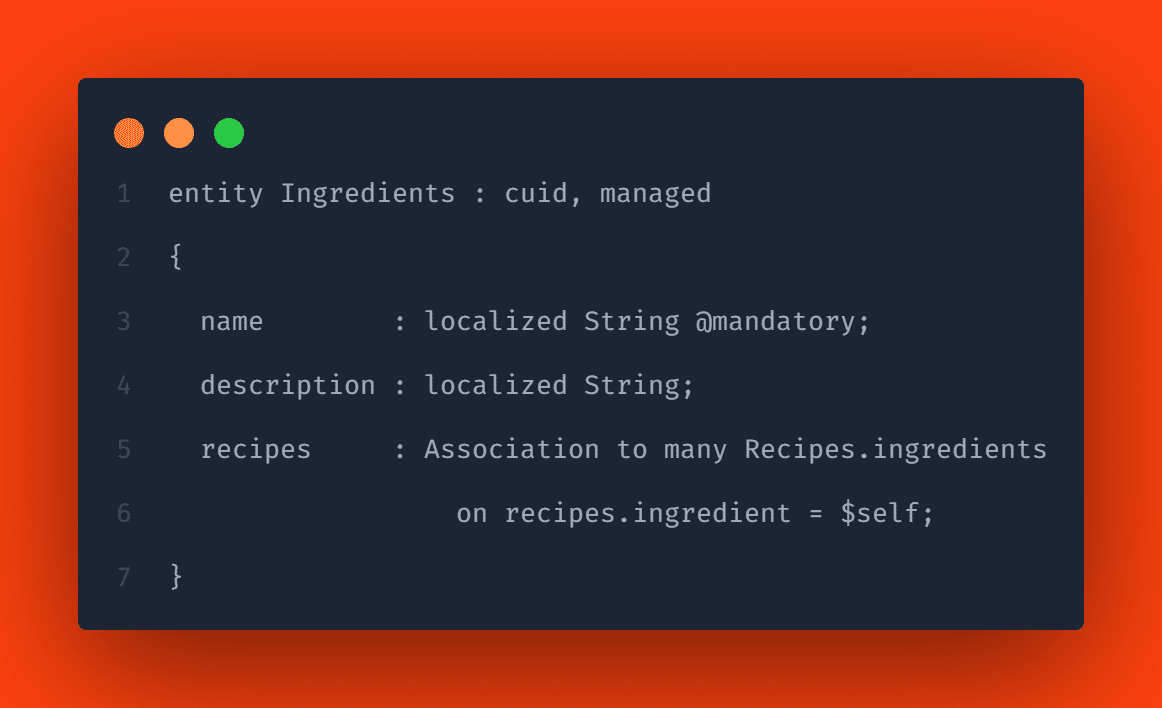
Sie möchten also mehrere Zutaten mit einem Rezept verknüpfen und so weitere Informationen hinzufügen, die nicht in den Zutaten selbst gespeichert sind. Darüber hinaus möchten Sie von einem Rezept zu seinen Zutaten und von einer Zutat zu den Rezepten navigieren, die sie enthalten. Dies ist ein Beispiel für eine attributierte Many-to-Many-Beziehung. In dem unten gezeigten Beispiel verwenden wir auch Inline-Ziele, d. h. wir geben keine Aspekte außerhalb der Entität selbst an.

Verwaltete Kompositionen sind in erster Linie nur eine vereinfachte Schreibweise. Hinter den Kulissen werden sie wie nicht verwaltete Kompositionen bereitgestellt, indem automatisch eine neue Entität hinzugefügt wird, deren Name CAP als scoped name aus dem Namen der übergeordneten Entität, gefolgt vom Namen des Kompositionselements, bildet, also „Recipes.Ingredients“ im vorherigen Beispiel.
Verwaltete Kompositionen sind praktisch für Many-to-Many-Beziehungen, bei denen eine Verknüpfungstabelle normalerweise nur für eine Seite privat ist. Bislang wissen wir jedoch nicht, wie wir von der einzelnen Zutat zum Rezept navigieren können. Das liegt daran, dass wir uns die Entität „Zutaten“ nicht angesehen haben. Schauen wir uns also die Entität „ingredients“ an, um dieses Problem zu lösen.
Das Laden der initialen Daten für Ihre Entitäten ist recht einfach. CSV-Dateien in Ihrem Projekt werden von Deployments sowohl für SQLite als auch für SAP HANA geholt. Es gelten jedoch ein paar Konventionen, die Sie beachten müssen.
Nach Konvention müssen sich Ihre csv-Dateien in einem db/csv-, db/data- oder db/src/csv-Ordner befinden. Eine einzelne csv-Datei enthält die Daten für jeweils eine Entität. Sie müssen außerdem dem Muster <Namensraum>-<Entitätsname>.csv folgen. Da wir in diesem Beispiel keinen Namensraum definiert haben, heißen die Dateien für unsere Entitäten „Recipes.csv“ und „Ingredients.csv“.
Die csv-Dateien müssen mit einer Kopfzeile beginnen, in der die erforderlichen Elementnamen aufgeführt sind. Lassen Sie uns also die Anfangsdaten für ein Rezept und zwei Zutaten bereitstellen, indem wir die beiden Dateien Recipes.csv und Ingredients.csv im Ordner db/data hinzufügen:
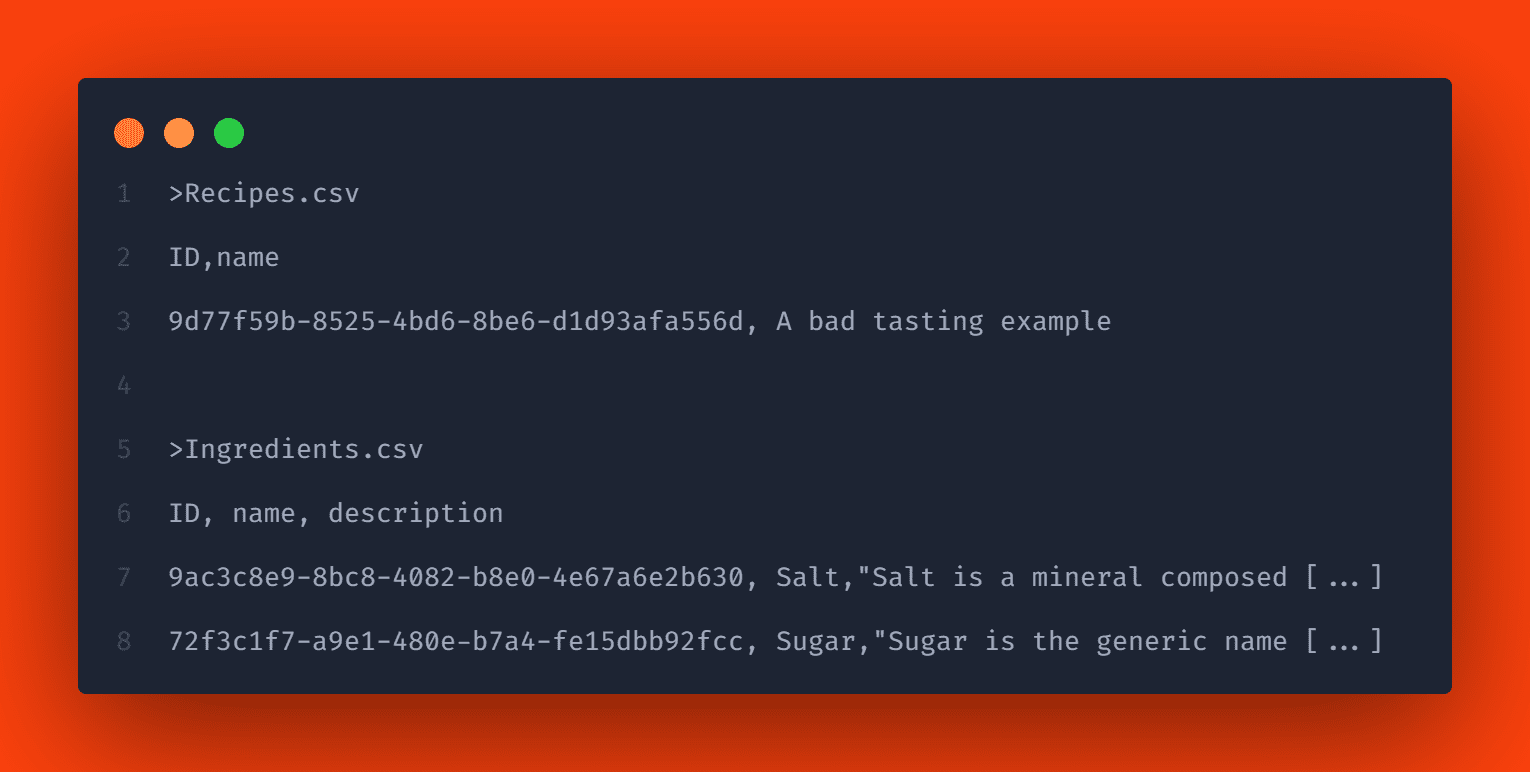
Wir haben bereits Daten für einige Attribute bereitgestellt. Wie Sie sehen können, können wir einen einzelnen Eintrag für die lokalisierten Zeichenfolgen hinzufügen. CAP wird den Eintrag verwenden, den wir mit der Standardsprache hinzugefügt haben. Als nächstes müssen wir also Übersetzungen für die lokalisierten Felder eingeben.
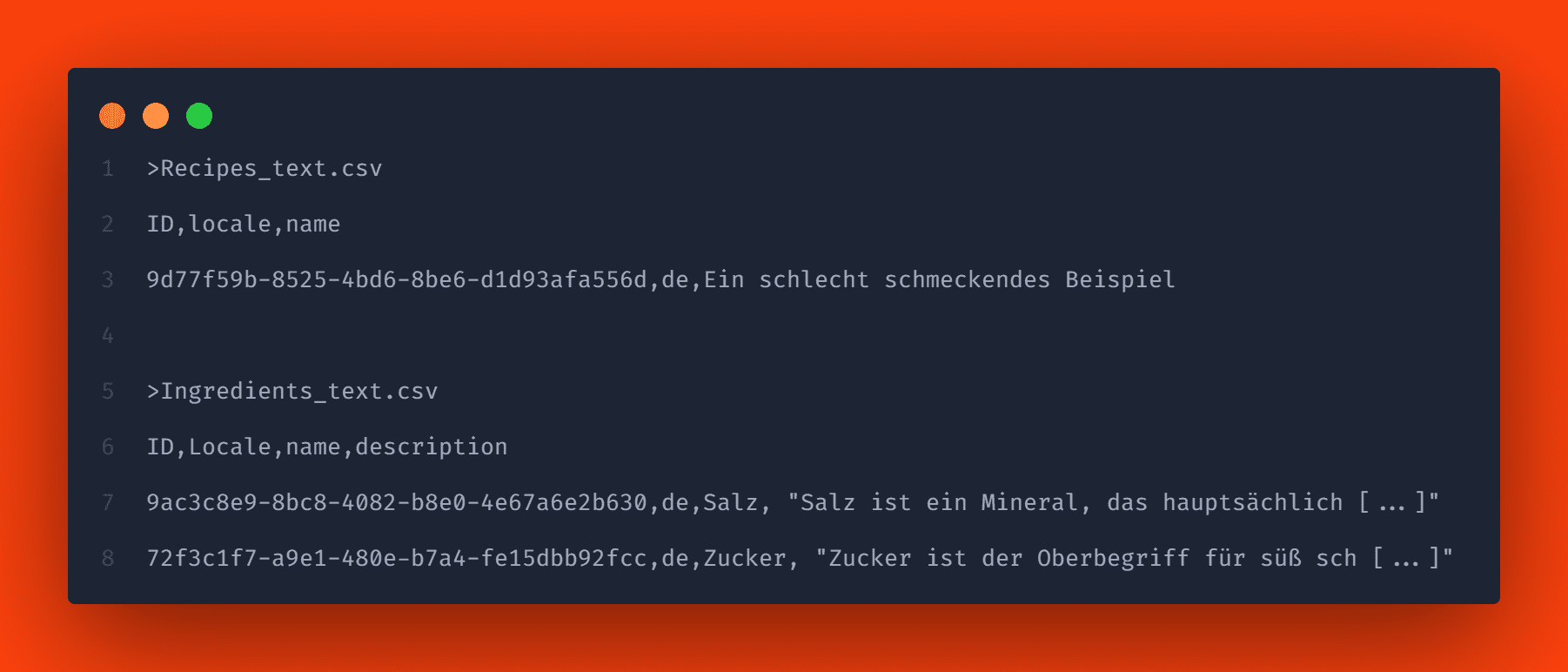
Um lokalisierte Strings hinzuzufügen, müssen Sie csv-Dateien mit dem gleichen Namensschema wie vor dem Anhängen von _texts erstellen. In unserem Beispiel also die csv-Dateien Recipes_texts.csv und Ingredients_texts.csv.
Nun, da die Entitätsdaten und Lokalisierungen vorliegen, lassen Sie uns die Komposition auffüllen. Das Benennungsschema ist hier <Namensraum>.<Entitätsname>-<Attribut>.csv. In unserem Beispiel würde dies der Datei Recipes-ingredients.csv entsprechen.
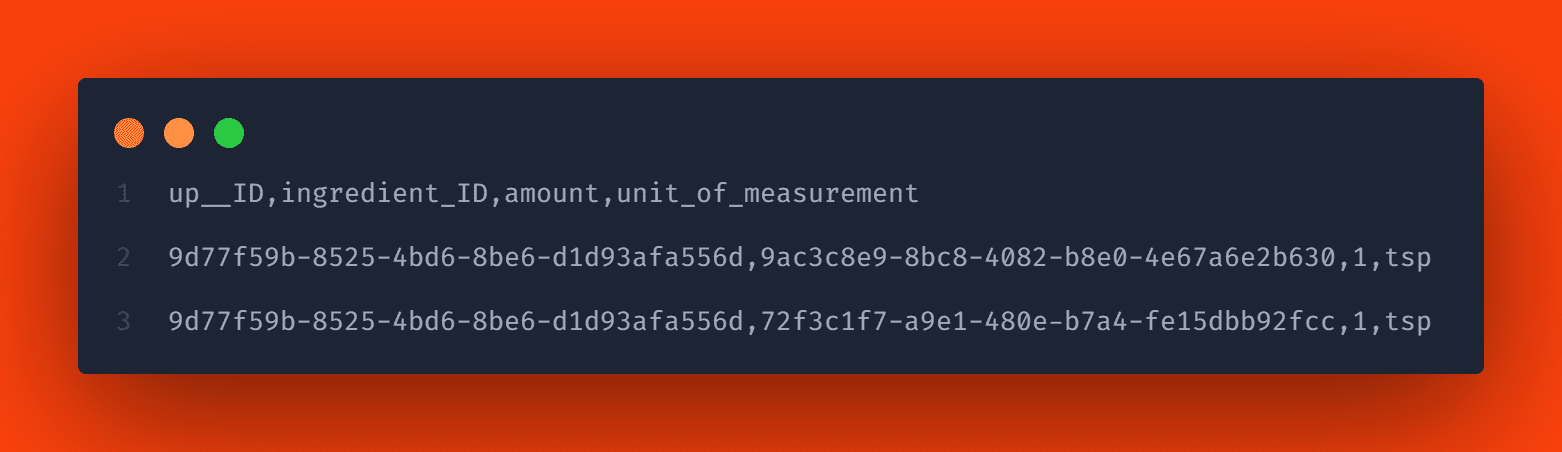
Diese csv-Datei enthält die Spalten up__ID und ingredients_ID. Die Spalte up__ID referenziert die enthaltende Entität (Recipe), die mit cuid das Schlüsselfeld ID besitzt. Die ingredients_ID-Spalte ist die Assoziation zur ingredient-Entität, die ebenfalls das Schlüsselfeld ID hat.
So richten Sie die initialen Dateien ein. Im nächsten Abschnitt sehen wir uns die Ergebnisse kurz in Aktion an.
Test mit einem einfachen Service durchführen
Um zu testen, ob die Daten von CAP hinzugefügt werden, können wir einen sehr einfachen Service erstellen. Erstellen Sie die Datei test-service.cds im Ordner srv und fügen Sie dort Projektionen zu den beiden Entitäten hinzu. Das könnte zum Beispiel so aussehen:
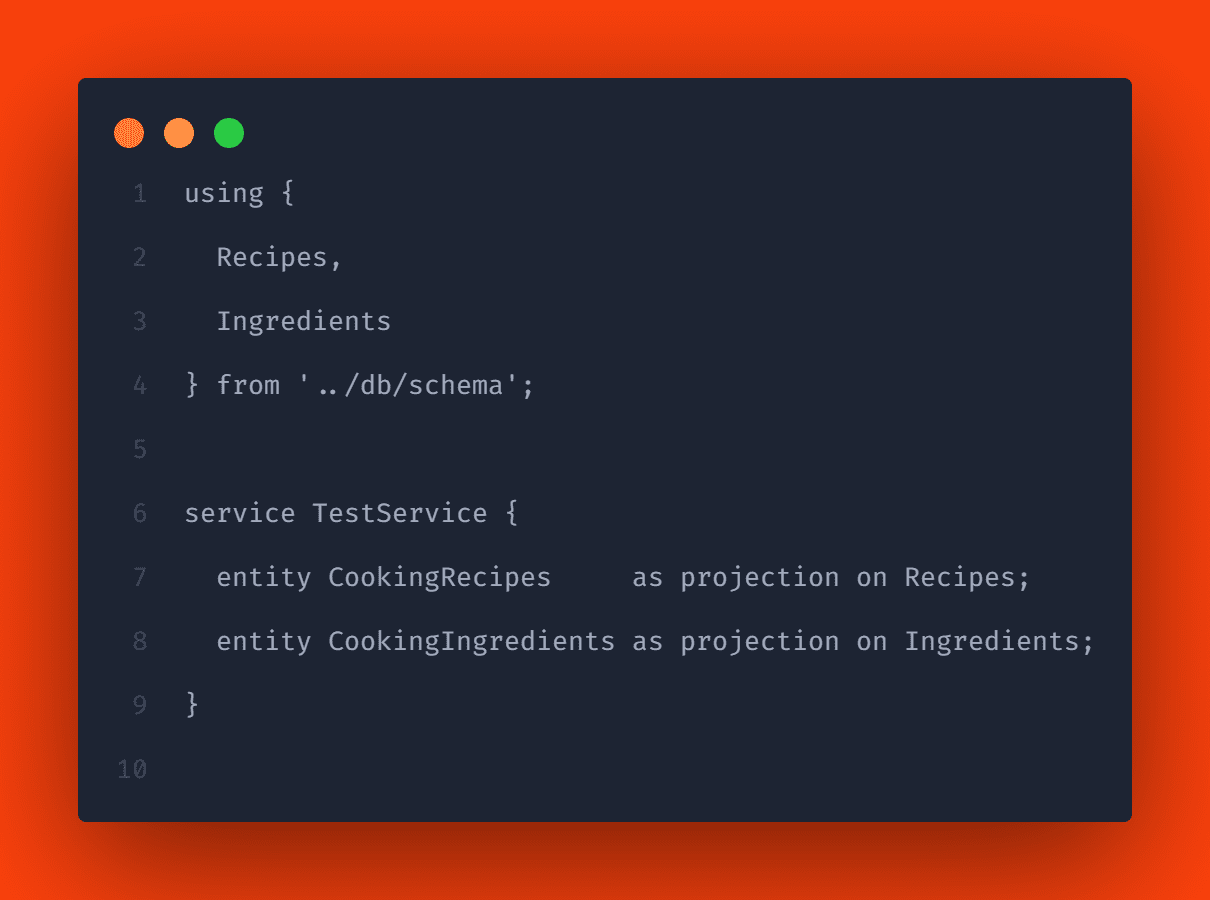
Wenn Sie nun cds watch im Terminal ausführen, sehen Sie eine Ausgabe, die besagt, dass die Dateien erkannt und ihr Inhalt automatisch in die Datenbank geladen wurde:
[cds] - connect to db > sqlite { database: ':memory:' }
[cds] - using bindings from: { registry: '~/.cds-services.json' }
> filling Ingredients from .\db\data\Ingredients.csv
> filling Ingredients.texts from .\db\data\Ingredients_texts.csv
> filling Recipes.ingredients from .\db\data\Recipes-ingredients.csv
> filling Recipes from .\db\data\Recipes.csv
> filling Recipes.texts from .\db\data\Recipes_texts.csv
/> successfully deployed to sqlite in-memory db
Das ist die Ausgabe, wenn Sie das Beispiel verwenden. Lassen Sie uns nun schnell den gestarteten Service verwenden, um einen Überblick zu bekommen. Zum Erweitern von Rezepten, um Zutaten anzuzeigen, verwenden Sie eine OData-Abfrage wie:
GET http://localhost:4004/test/CookingRecipes?$expand=ingredients($expand=ingredient)
Wie Sie feststellen werden, sind die Antworten deutsch, da wir die Lokalisierung eingegeben haben und die Standardsprache meines Browsers deutsch ist.

Lassen Sie uns den umgekehrten Weg von einer Zutat zu einem Rezept gehen, aber diesmal mit englischen Ergebnissen. Hierfür verwenden wir eine Abfrage wie:
GET http://localhost:4004/test/CookingIngredients?$expand=recipes($expand=up_)&sap-language=en
Sie werden eine Antwort erhalten wie beispielsweise:
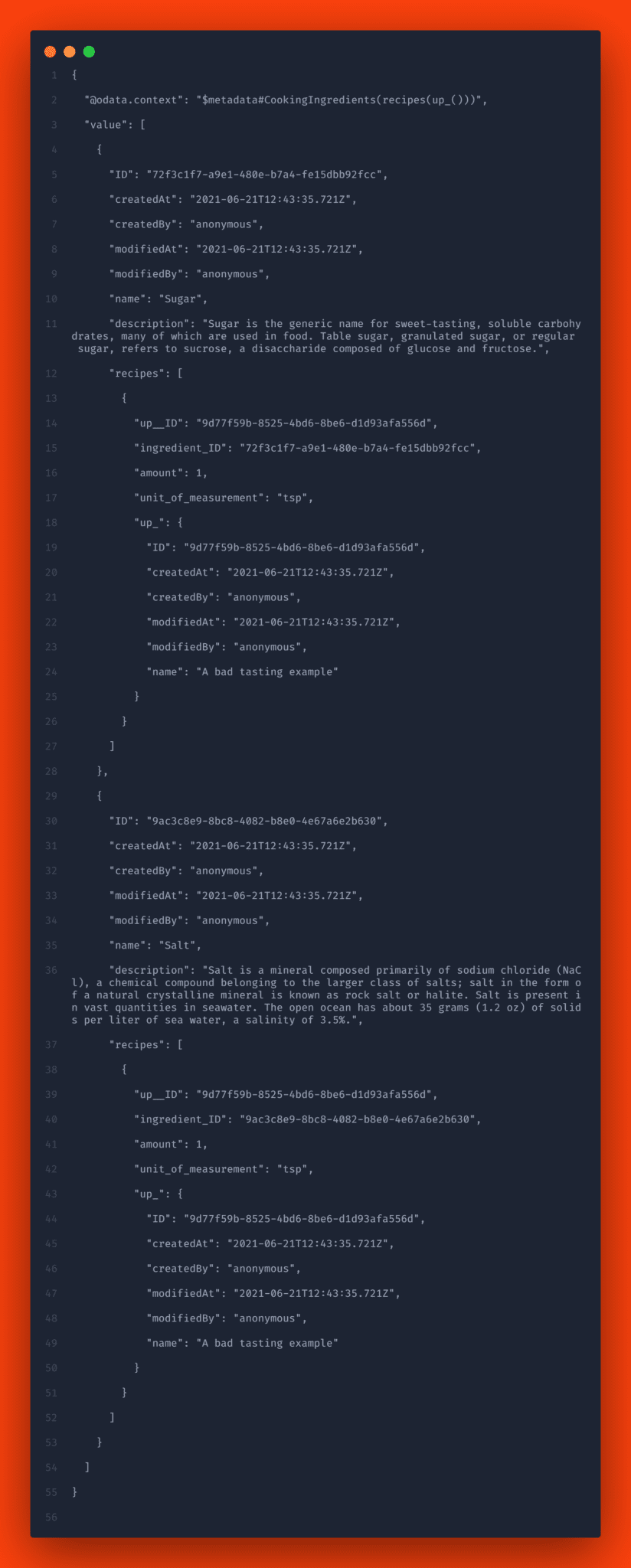
Lassen Sie uns kurz rekapitulieren. Sie verwenden Compositions für die dokumentenorientierte Modellierung und erfassen Beziehungen, die in Entitäten enthalten sind. Sie können Many-to-Many-Beziehungen mit Compositions of Aspects modellieren.
Die CAP-Laufzeiten bieten Out-of-the-Box-Unterstützung für die Bereitstellung strukturierter Dokumentdaten durch generische Service-Provider-Implementierungen.
Sie können Ausgangsdaten für Compositions of Aspects bereitstellen, indem Sie csv-Dateien mit dem Namensschema <Namensraum>.<Entität>-<Attribut> erstellen und Referenzen auf die enthaltende Entität bereitstellen, indem Sie Spalten zu den Schlüsselfeldern der enthaltenden Entität bereitstellen, die mit up__ beginnen.
Wenn Sie weitere Fragen zu diesem Thema haben, hinterlassen Sie uns bitte eine Nachricht.


